Key Takeaways
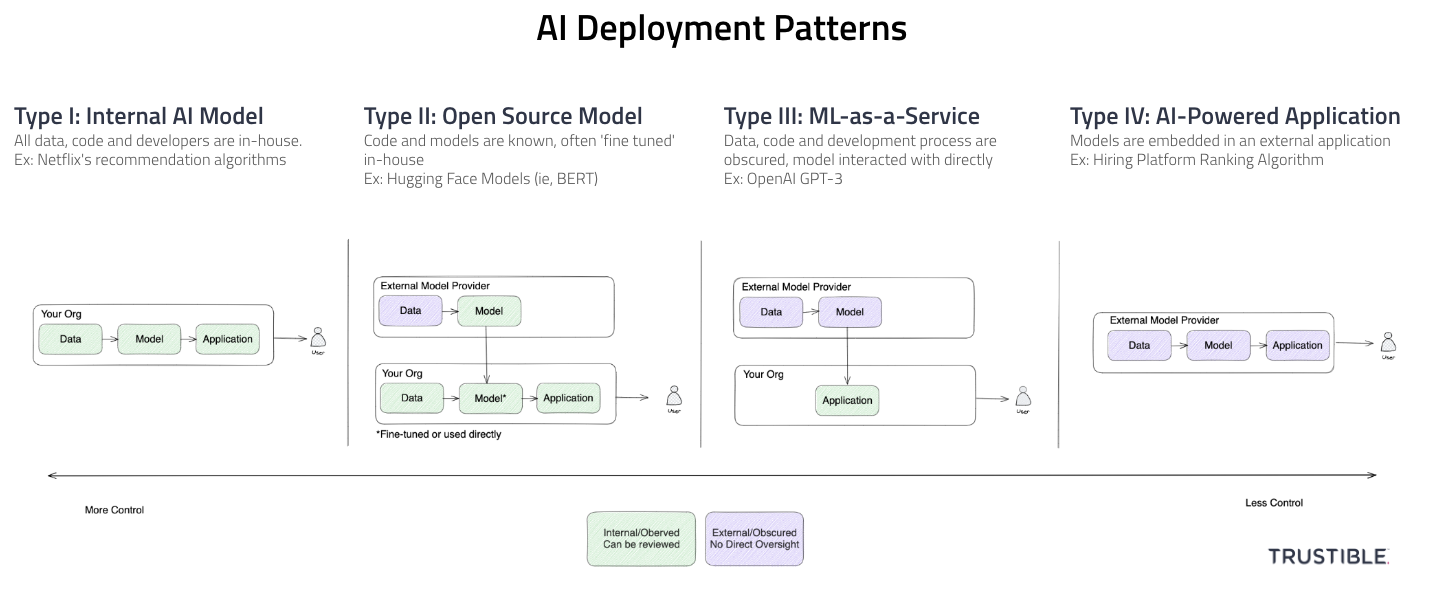
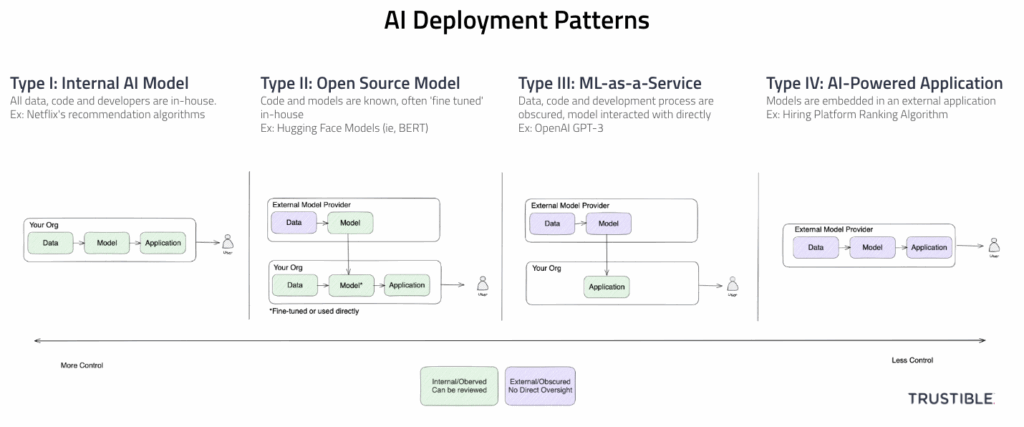
- 4 Broad patterns for AI system deployments (Internal, Open Source Model, ML-as-a-Service, AI Powered Application)
- Varying levels of organizational risks and AI Governance needs by pattern
- Type-III (ML-as-a-Service) has the highest risks and governance challenges because of low visibility and low liability and risk transference
As the deployment of AI becomes pervasive, many teams from across your organization need to get involved with AI Governance, not only the data scientists and engineers. With increasing government regulation and reputational risks, it’s more essential that all stakeholders work with a consistent framework of categorizing different patterns of AI deployments. This blog post offers one high level framework for categorizing different AI deployment patterns and discusses some of the AI Governance challenges associated with each pattern.
Type I – Internal Model
In a Type-I deployment, your organization is responsible for the end-to-end development of the AI capabilities – sourcing your own data, writing the code to build your own model, and deploying it into production. You may collect data from public sources, or use open source libraries for machine learning, but the differentiating factor is that you have full visibility and control over the entire ML lifecycle. Because you have full access and ownership over all components of your AI system, you are therefore responsible for all legal liability and regulatory compliance. This includes inspecting training data and models for biases, monitoring systems in production, and responding to reported incidents.
Examples:
- Netflix’s movie recommendation algorithm
- Google’s search ranking algorithm
Governance Considerations – Many of the biases in AI systems stem from the original training data used for the model, as well as the design decisions about the model including feature selection and output categories/classes. Your organizations should ensure that the training data being used was generated legally and ethically, that it is a representative sample of the population that the AI system will be used on, and that its characteristics, including key demographic breakdowns (if any) are well documented. Similarly, once a model has been created, your organization should closely inspect it to ensure it functions as expected, with high accuracy and resiliency from possible adversarial attacks against it. These model checks should be done before the model gets deployed, as well as at regular intervals afterwards to ensure that the model continues to function as expected over time. Finally, your organization will be responsible for all aspects of monitoring the AI systems and responding to user feedback and incidents. This pattern does involve the most upfront work for your organization, but it also offers your organization the highest level of control and visibility over your AI deployment.
Type II – Open Source Model
In a Type-II deployment pattern, your organization is using a publicly available base ML model from an external source that can be downloaded and then adapted for a specific use case. The main difference between a Type-I deployment and a Type-II deployment is that some amount of training has already been done, and therefore biases in the base data or model may be present. However, you are able to inspect and probe the model for biases at will and without legal conditions. This pattern may still involve a secondary training step (often called ‘fine tuning’) where the pre-trained model is then given a new set of examples or a new task and is trained on that. This fine-tuning may introduce new biases and risks. This deployment pattern still requires a high level of internal governance as almost all the legal liability will still be with you as the system deployer, and almost none with the open source model provider.
Examples:
- Fine tuning a BERT or BLOOM model (HuggingFace Open Source Project) to summarize news articles
- Using a pre-trained sentiment classifier to analyze tweets
Governance Considerations – This deployment pattern introduces risk associated with a vendor, even if that ‘vendor’ is a highly transparent research group creating open source models with clear data sources. Keep in mind that even the ‘best’ organizations that publish these models (e.g.: HuggingFace) do not always disclose all information about the training datasets used, and they are not always accessible to inspect yourself. ML development teams often like using these open source models especially for new ideas as they allow for faster experimental iteration at lower costs both in terms of developer time and compute.
From the risk mitigation standpoint, the fact that these models are provided through open source licenses means that there is no ability to ‘transfer’ the risk through a services agreement between your organization and the model provider, despite there being potential biases in the models. The best approach here is to spend time probing and analyzing these open source models to understand their limitations and biases, and then identify downstream evaluation tasks to prevent these biases from affecting downstream users. This is in addition to all other governance tasks including ensuring any data used for ‘fine tuning’ is robust and appropriate, and that testing is in place to ensure the resulting model is appropriate for the task.
Type III – ML-as-a-service
For a Type-III deployment, the model your organization is using is developed and hosted by a third party and considered proprietary. In this case, your organization may be highly limited in what it knows about the training data, how the model is constructed, or what biases have been tested for. Oftentimes the model is accessed through an API or other cloud service, as downloading it would allow for easy inspection and backwards engineering. The inputs to these models are oftentimes more or less ‘directly’ fed into the model with minimal additional work done before or after the model’s inputs/outputs.
Examples:
- Using GPT-3 to summarize news documents
- Using Google Translate API to translate news articles
Governance Considerations – This deployment pattern is the newest of the four approaches, but one that has gotten the most press and attention recently. This approach also likely has the highest risks associated with it for the organization using it. In this approach, you likely have very little information about the data and ML model, but because you can use it for your own use cases that the provider cannot know about or enforce, the terms of service limit the liability of the model provider. This means that very little of your organizational risks can get ‘transferred’ to the provider. Furthermore, since these models are hosted in a cloud system, a lot of your own proprietary data may get logged and stored in the model provider’s systems which represents serious privacy, security and intellectual property concerns. As a final point of concern, the actual ML model hosted by the provider can change at any time without you knowing about it. That could include changes which introduce new training data and hence new biases, or a change in the model’s structure which impacts the stability of its outputs.
Best practices for governance of this deployment approach are still actively being discussed, but it must start with getting as much understanding from the vendor about their processes, model evaluation/testing criteria and how they handle rolling out new model versions. After that, ensuring you have your own suite of tools for validating that the hosted model is appropriate for your tasks and robust enough for your use case is the next best step. The final additional step is ensuring there are very clear internal guidelines for what kind of data can be passed into the ML model’s API and enforcement mechanisms to support those guidelines.
Type IV – AI Powered Application
In Type-IV deployments, the model is not directly accessible in any way, including by an API. Instead, the model is ‘deeply’ embedded in some other application that you are using. The main difference here is that there may be a lot of additional information flowing into the model that you have no visibility into, and the results are then pre-interpreted for you and are delivered back to you in a web application or other abstract format. For a clear line between the Type-III and Type-IV patterns in the generative AI space, with a Type-IV deployment, you may not be aware of what prompt is being used or what parameters are being set on the API calls.
Examples:
- Using Microsoft Office’s AI features powered by GPT-4
- Using a tool to generate emails based on information in Salesforce
Governance Consideration – This approach carries with it some of the similar concerns as the ML-as-a-service approach, but the specific context and use case means the vendor is more likely to have their own additional testing and validation layers and have a very large incentive to ensure their AI system is trustworthy and responsible for their specific use case. In addition, your organization can negotiate better terms of service, and an application can be deployed in a secure way inside of a company’s network without compromising the actual models or proprietary IP of the provider.
Just because the AI is wrapped in another application obviously doesn’t absolve your organization from monitoring or ensuring proper governance policies have been enforced. For example, since your organization isn’t able to directly access training data to evaluate it, requesting a datasheet from the provider, or some third party audit that attests to the appropriateness of the training data set would be an appropriate step. One risk present with this approach more than others is that buyers of these systems may not be well versed on AI systems and their appropriate risks. In other deployment models, there are likely technical developers involved with the integration, however in this model, the buyer could be on any team and the buyer may not be aware of what documents to request from the vendor, nor how to evaluate them. The appropriate governance mitigation here is to then ensure an AI-savvy team is involved in the procurement and validation process.
Final Thoughts – This blog post does not aim to be comprehensive of all the different deployment approaches, nor comprehensive about all the various governance tasks that should be conducted. However, it does offer a useful high-level framework for how to organize an organization’s use of AI and some of the governance challenges associated with each one.